Trong bối cảnh thị trường laptop đa dạng với hàng ngàn mẫu mã và cấu hình, việc tìm kiếm một chiếc máy phù hợp với mức giá hợp lý có thể trở thành một thách thức lớn. Người tiêu dùng thường phải dành vô số giờ lướt qua các trang web, so sánh thông số và giá cả, đối mặt với rủi ro chi tiêu quá mức hoặc bỏ lỡ một ưu đãi tốt. Tại trithuccongnghe.net, chúng tôi hiểu rằng kiến thức và công cụ phù hợp sẽ giúp bạn đưa ra quyết định sáng suốt hơn. Bài viết này sẽ đi sâu vào cách chúng ta có thể tận dụng sức mạnh của ngôn ngữ lập trình Python và các thư viện phân tích dữ liệu để xây dựng một mô hình dự đoán giá laptop, giúp bạn tự tin hơn khi lựa chọn sản phẩm công nghệ.
Tại Sao Cần Xây Dựng Công Cụ Dự Đoán Giá Laptop?
Việc tìm kiếm một chiếc laptop mới đòi hỏi nhiều hơn là chỉ duyệt qua vài trang web. Với hàng ngàn mẫu máy tính xách tay khác nhau trên thị trường, từ các thông số kỹ thuật như bộ xử lý, RAM, dung lượng lưu trữ, đến kích thước màn hình và trọng lượng, việc so sánh thủ công trở nên vô cùng tốn thời gian và dễ gây nhầm lẫn. Nhiều người thường cảm thấy choáng ngợp trước biển thông tin và có thể dễ dàng bị ảnh hưởng bởi các yếu tố marketing, dẫn đến việc mua phải sản phẩm không thực sự tối ưu về giá trị.
Chúng tôi tin rằng mọi người đều muốn mua một chiếc laptop với mức giá công bằng, không quá đắt mà vẫn đáp ứng đủ nhu cầu. Đó là lý do một công cụ dự đoán giá tự động trở nên vô cùng hữu ích. Tưởng tượng bạn có thể nhập các thông số kỹ thuật mong muốn như lượng RAM, độ phân giải màn hình hay tốc độ CPU, và ngay lập tức nhận được một ước tính giá hợp lý. Điều này không chỉ giúp tiết kiệm thời gian mà còn mang lại sự khách quan, dựa trên dữ liệu thực tế thay vì cảm tính hay quảng cáo. Với kiến thức về hồi quy tuyến tính từ thống kê, chúng tôi nhận ra rằng việc xây dựng một mô hình như vậy bằng Python là hoàn toàn khả thi và hiệu quả. Python, với sự đơn giản và các thư viện mạnh mẽ, đã trở thành lựa chọn hàng đầu trong phân tích dữ liệu, ngay cả với những người không có nền tảng khoa học máy tính chuyên sâu.
 Laptop Lenovo Yoga Slim 9i Gen 10 trên bàn làm việc, ví dụ về thiết bị cần dự đoán giá.
Laptop Lenovo Yoga Slim 9i Gen 10 trên bàn làm việc, ví dụ về thiết bị cần dự đoán giá.
Bộ Công Cụ Thống Kê Python Cho Dự Án
Để thực hiện dự án xây dựng mô hình dự đoán giá laptop, chúng tôi sẽ sử dụng một số thư viện Python phổ biến trong hệ sinh thái phân tích dữ liệu và khoa học máy tính. Đây là những công cụ đã được thử nghiệm và chứng minh về hiệu quả, giúp đơn giản hóa các tác vụ phức tạp.
Quản lý Môi Trường với Mamba/VirtualEnv
Mặc dù nhiều hệ điều hành (bao gồm Linux) đã cài đặt sẵn Python, nhưng phiên bản đó thường được dùng để hỗ trợ hệ thống. Việc nâng cấp hoặc thay đổi phiên bản Python hệ thống có thể gây ra lỗi cho các script phụ thuộc. Để tránh xung đột và quản lý các gói thư viện một cách độc lập, chúng tôi khuyến nghị sử dụng các công cụ quản lý môi trường ảo như Mamba hoặc VirtualEnv. Điều này giúp tạo ra một môi trường riêng biệt cho từng dự án, đảm bảo tính ổn định và khả năng tái lập.
NumPy: Nền Tảng Tính Toán Số Học
NumPy (Numerical Python) là một thư viện cốt lõi trong Python, cung cấp các cấu trúc dữ liệu mảng hiệu quả và các hàm cho phép thực hiện các phép toán số học, đặc biệt là các tính toán thống kê và đại số tuyến tính. Trong dự án này, NumPy sẽ hoạt động ở nền tảng, hỗ trợ các thư viện khác thực hiện các phép tính phức tạp một cách nhanh chóng.
Pandas: Xử Lý và Phân Tích Dữ Liệu Hiệu Quả
Pandas là thư viện không thể thiếu cho việc làm việc với dữ liệu có cấu trúc. Nó cung cấp cấu trúc dữ liệu DataFrame, tương tự như một bảng trong cơ sở dữ liệu quan hệ hoặc một bảng tính Excel. Pandas cho phép bạn nhập dữ liệu từ nhiều nguồn khác nhau (như file CSV), xem, làm sạch và thực hiện các thao tác mạnh mẽ trên dữ liệu, biến nó thành định dạng phù hợp cho việc phân tích.
Seaborn: Trực Quan Hóa Dữ Liệu Chuyên Nghiệp
Seaborn là một thư viện trực quan hóa dữ liệu được xây dựng dựa trên Matplotlib, chuyên dùng để tạo các biểu đồ thống kê đẹp mắt và có tính thông tin cao. Chúng tôi sẽ sử dụng Seaborn để vẽ các biểu đồ phân phối dữ liệu như biểu đồ tần suất (histograms), biểu đồ phân tán (scatterplots) và các biểu đồ hồi quy tuyến tính, giúp chúng ta hiểu rõ hơn về mối quan hệ giữa các biến.
![]() Logo Seaborn và biểu đồ minh họa khả năng trực quan hóa dữ liệu trong Python.
Logo Seaborn và biểu đồ minh họa khả năng trực quan hóa dữ liệu trong Python.
Pingouin: Thư viện Kiểm Định Thống Kê Mạnh Mẽ
Pingouin là một thư viện thống kê mạnh mẽ, cung cấp nhiều hàm kiểm định thống kê và phân tích dễ sử dụng. Với Pingouin, chúng ta có thể thực hiện các kiểm định như hồi quy tuyến tính đa biến (multiple linear regression) mà không cần phải ghi nhớ tất cả các công thức phức tạp. Đây là công cụ chính giúp chúng tôi xây dựng mô hình dự đoán giá và kiểm định các giả thuyết thống kê.
Môi Trường Phát Triển: Jupyter Notebook
Jupyter Notebook là một môi trường tương tác thân thiện với người dùng, cho phép bạn viết và chạy các lệnh Python, xem kết quả, và lưu trữ toàn bộ quy trình dưới dạng một tài liệu duy nhất. Nó đặc biệt hữu ích cho phân tích dữ liệu và trình bày các bước thực hiện. Chúng tôi sẽ minh họa các ví dụ mã lệnh trong bài viết này bằng cách sử dụng Jupyter Notebook. Bạn có thể tìm thấy toàn bộ mã nguồn trên GitHub của chúng tôi.
Để bắt đầu, bạn cần kích hoạt môi trường đã cài đặt các thư viện trên. Ví dụ, nếu bạn dùng Mamba, bạn gõ lệnh sau vào terminal:
mamba activate statsThu Thập Dữ Liệu Laptop
Để xây dựng một mô hình hồi quy đáng tin cậy, dữ liệu chất lượng là yếu tố then chốt. Việc tự thu thập dữ liệu về hàng ngàn mẫu laptop từ các cửa hàng trực tuyến sẽ tốn rất nhiều thời gian và công sức, chưa kể đến giai đoạn làm sạch và chuẩn hóa dữ liệu để đảm bảo tính nhất quán. May mắn thay, đã có người thực hiện công việc này.
Chúng tôi sẽ sử dụng một bộ dữ liệu về laptop có sẵn trên Kaggle, một nền tảng cộng đồng dành cho khoa học dữ liệu. Bộ dữ liệu này bao gồm các thông số phần cứng quan trọng như tốc độ CPU, dung lượng RAM, dung lượng lưu trữ chính và phụ, độ phân giải màn hình (chiều rộng và chiều cao), cùng với giá bán của các mẫu laptop.
Giá của các laptop trong bộ dữ liệu được ghi bằng Euro. Tuy nhiên, một kiểm tra nhanh vào tháng 7 năm 2025 trên Xe.com cho thấy tỷ giá hối đoái giữa Euro và Đô la Mỹ khá sát nhau, nên việc này sẽ không ảnh hưởng đáng kể đến mô hình của chúng ta.
Xây Dựng Mô Hình Hồi Quy Dự Đoán Giá
Sau khi đã chuẩn bị môi trường và thu thập dữ liệu, đây là lúc chúng ta tiến hành xây dựng mô hình dự đoán giá.
Đầu tiên, chúng ta cần nhập các thư viện Python sẽ được sử dụng:
import numpy as np
import pandas as pd
import seaborn as sns
%matplotlib inline
import pingouin as pgCác dòng code trên nhập các thư viện NumPy, Pandas, Seaborn và Pingouin, đồng thời rút gọn tên của chúng thành “np, pd, sns, và pg” để dễ sử dụng hơn. Dòng %matplotlib inline là một lệnh đặc biệt dành cho Jupyter Notebook, yêu cầu hiển thị các biểu đồ được vẽ bởi Matplotlib ngay bên trong notebook thay vì mở trong một cửa sổ riêng.
Tiếp theo, chúng ta sẽ nhập dữ liệu laptop từ file CSV bằng thư viện Pandas:
laptops = pd.read_csv("data/laptop_prices.csv")Lệnh này sẽ tạo ra một DataFrame của Pandas. Để xem cấu trúc và 5 dòng dữ liệu đầu tiên của DataFrame, chúng ta sử dụng phương thức head():
laptops.head()Ngoài ra, chúng ta có thể xem các thống kê mô tả cơ bản của tất cả các cột số học bằng phương thức describe():
laptops.describe()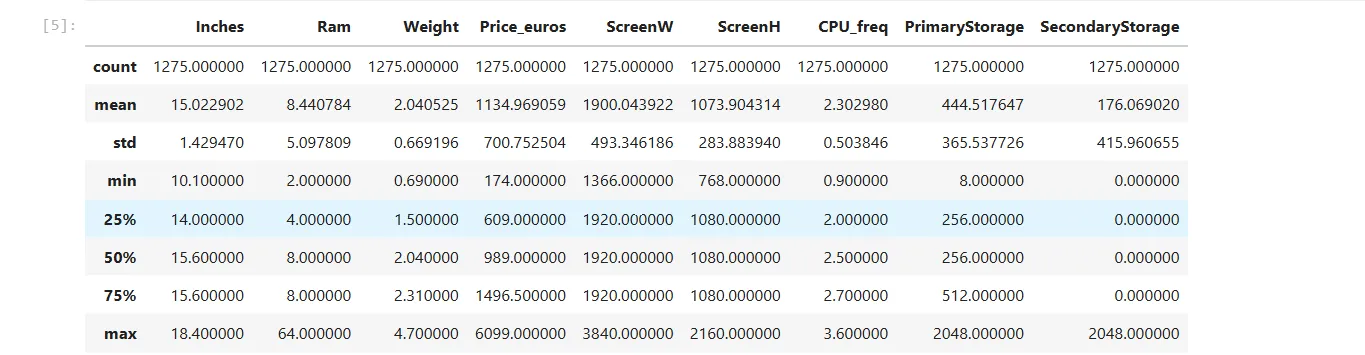 Bảng thống kê mô tả các thuộc tính số của dữ liệu laptop, hiển thị trung bình, độ lệch chuẩn.
Bảng thống kê mô tả các thuộc tính số của dữ liệu laptop, hiển thị trung bình, độ lệch chuẩn.
Bảng thống kê này cung cấp các thông tin hữu ích như giá trị trung bình (mean), độ lệch chuẩn (standard deviation), giá trị nhỏ nhất (min), các tứ phân vị (25%, 50%, 75%) và giá trị lớn nhất (max) cho mỗi cột dữ liệu số.
Chúng tôi cũng thích trực quan hóa phân phối dữ liệu thông qua biểu đồ tần suất (histograms). Hàm displot của Seaborn sẽ giúp chúng ta thực hiện điều này. Để xem phân phối giá laptop:
sns.displot(x='Price_euros',data=laptops)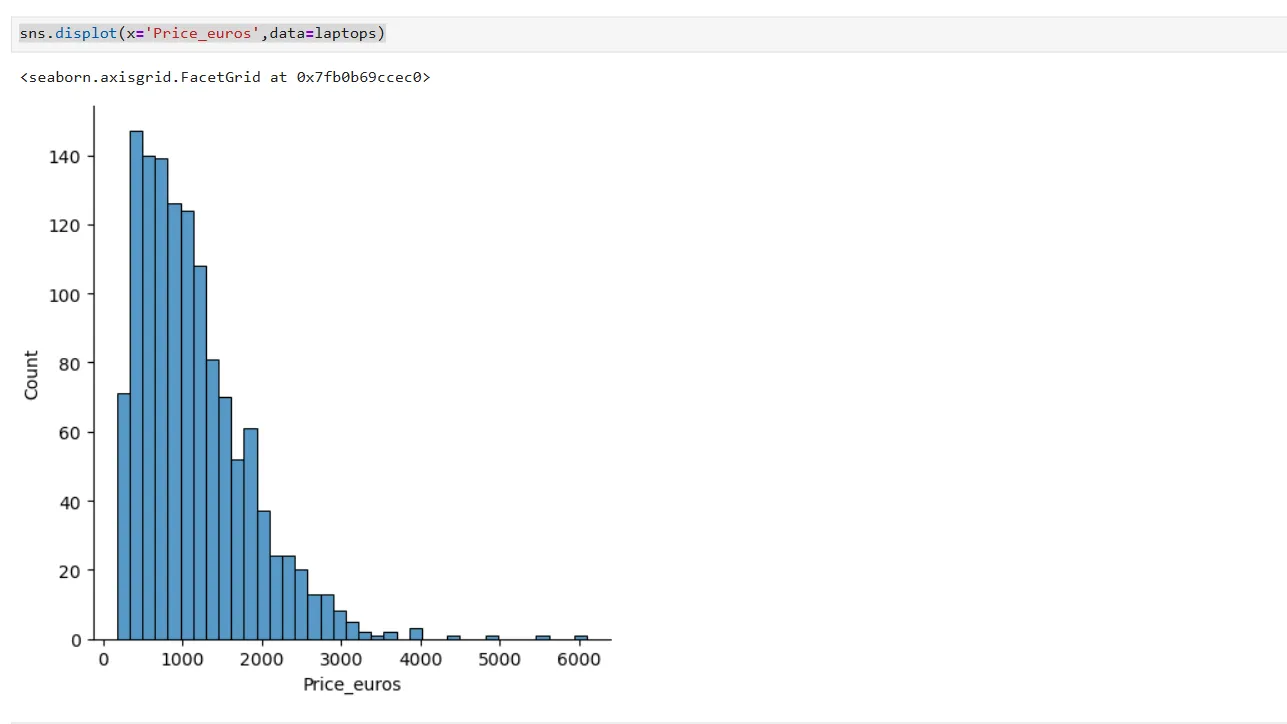 Biểu đồ tần suất (histogram) phân bố giá laptop bằng Euro, được tạo trong Jupyter Notebook.
Biểu đồ tần suất (histogram) phân bố giá laptop bằng Euro, được tạo trong Jupyter Notebook.
Biểu đồ này cho thấy phân phối giá có đuôi lệch rõ rệt về phía bên phải, chỉ ra rằng có nhiều laptop ở phân khúc giá thấp và một số ít laptop ở phân khúc giá rất cao.
Chúng ta sẽ xây dựng một mô hình dự đoán giá sử dụng nhiều thông số kỹ thuật khác nhau. Mô hình sẽ có dạng tương tự như sau:
giá = a(tốc độ CPU) + b(RAM) + c(kích thước màn hình) + …
Các chữ cái (a, b, c…) là các hệ số được xác định bởi quá trình hồi quy. Điều này tương tự như hồi quy tuyến tính đơn giản mà bạn có thể đã thấy, nhưng thay vì khớp một đường thẳng trên biểu đồ phân tán, chúng ta đang khớp một mặt phẳng hoặc siêu mặt phẳng trong không gian đa chiều (do có nhiều hơn ba biến).
Để thực hiện hồi quy giá (bằng Euro) theo các thuộc tính của laptop như kích thước (inch), RAM, trọng lượng, độ rộng và chiều cao màn hình (ScreenW, ScreenH), tần số CPU (CPU_freq), dung lượng lưu trữ chính (PrimaryStorage) và lưu trữ phụ (SecondaryStorage), chúng ta sử dụng hàm linear_regression của Pingouin:
pg.linear_regression(laptops[['Inches','Ram','Weight','ScreenW','ScreenH','CPU_freq','PrimaryStorage','SecondaryStorage']],laptops['Price_euros'],relimp=True)Lệnh này sẽ trả về các hệ số cho phương trình hồi quy. Cột ngoài cùng bên trái hiển thị các hệ số, trong khi cột ngoài cùng bên phải cho biết mức độ đóng góp của mỗi biến vào việc dự đoán giá. Chúng ta có thể thấy RAM là yếu tố dự đoán giá mạnh nhất. Chỉ số r2 (bình phương hệ số tương quan) trong bảng này cho biết mức độ phù hợp của mô hình, khoảng 0.66, đây là một con số khá tốt, cho thấy mô hình giải thích được khoảng 66% sự biến động của giá.
Với các hệ số dự đoán này, chúng ta có thể tạo một hàm để cắm các giá trị vào và dự đoán giá:
def price(inches,ram,weight,screenw,screenh,cpu_freq,primary_storage,secondary_storage):
return 77.11 + -69.81*inches + 77.89*ram + 92.04*ram + 0.04*screenw + 0.59*screenh + 284.51 - 0.21*primary_storage + -0.04 * secondary_storageLưu ý: Dòng thứ hai trong hàm price phải được thụt lề để đảm bảo cú pháp Python hợp lệ.
Giá Laptop Có Thực Sự Khác Biệt Giữa Các Thương Hiệu? (Phân tích ANOVA)
Mô hình hồi quy chúng ta vừa xây dựng chỉ tập trung vào các thông số kỹ thuật. Tuy nhiên, một câu hỏi phổ biến khác là liệu thương hiệu (Company) có phải là một yếu tố quan trọng ảnh hưởng đến giá laptop hay không. Để trả lời câu hỏi này, chúng ta có thể sử dụng phân tích phương sai (ANOVA). Vì dữ liệu giá có sự phân phối lệch (như đã thấy ở biểu đồ tần suất), một kiểm định phi tham số sẽ chính xác hơn. Pingouin cung cấp kiểm định Kruskal-Wallis phù hợp cho trường hợp này.
Kiểm định Kruskal-Wallis sẽ kiểm tra giả thuyết không (null hypothesis) rằng không có mối quan hệ nào giữa giá và thương hiệu. Nói cách khác, giả thuyết này cho rằng giá trung bình của laptop là như nhau giữa tất cả các thương hiệu.
pg.kruskal(data=laptops,dv='Price_euros',between='Company').round(2) Kết quả kiểm định Kruskal-Wallis về sự khác biệt giá giữa các thương hiệu laptop, hiển thị p-value.
Kết quả kiểm định Kruskal-Wallis về sự khác biệt giá giữa các thương hiệu laptop, hiển thị p-value.
Kết quả kiểm định Kruskal-Wallis cho ra giá trị p-value là 0 (sau khi làm tròn đến 2 chữ số thập phân). Một p-value nhỏ (thường nhỏ hơn 0.05) cho phép chúng ta bác bỏ giả thuyết không. Điều này có nghĩa là có sự khác biệt có ý nghĩa thống kê về giá giữa các thương hiệu laptop. Nói cách khác, thương hiệu thực sự là một yếu tố dự đoán giá.
Kết Luận
Qua bài viết này, chúng ta đã cùng nhau khám phá cách xây dựng một công cụ dự đoán giá laptop hiệu quả bằng Python. Từ việc thu thập dữ liệu, lựa chọn và sử dụng các thư viện mạnh mẽ như NumPy, Pandas, Seaborn và Pingouin, cho đến việc áp dụng các phương pháp thống kê như hồi quy tuyến tính và kiểm định Kruskal-Wallis, chúng ta đã tạo ra một mô hình có khả năng ước tính giá dựa trên thông số kỹ thuật và thậm chí phân tích được ảnh hưởng của thương hiệu đến giá cả.
Việc sở hữu một mô hình dự đoán giá như thế này mang lại lợi ích to lớn cho người tiêu dùng, giúp họ đưa ra quyết định mua sắm sáng suốt hơn, tránh việc chi tiêu quá mức và đảm bảo nhận được giá trị tốt nhất cho sản phẩm. Đây là một minh chứng rõ ràng về sức mạnh của Python và hệ sinh thái thư viện của nó trong việc giải quyết các vấn đề thực tế, biến những tác vụ phức tạp thành những dòng mã đơn giản và hiệu quả.
Hãy tiếp tục theo dõi trithuccongnghe.net để khám phá thêm nhiều ứng dụng thú vị khác của công nghệ và lập trình trong đời sống hàng ngày! Nếu bạn có bất kỳ câu hỏi hoặc muốn chia sẻ kinh nghiệm, đừng ngần ngại để lại bình luận phía dưới.